Welcome to the Data Score newsletter, composed by DataChorus LLC. The newsletter is your go-to source for insights into the world of data-driven decision-making. Whether you're an insight seeker, a unique data company, a software-as-a-service provider, or an investor, this newsletter is for you. I'm Jason DeRise, a seasoned expert in the field of data-driven insights. As one of the first 10 members of UBS Evidence Lab, I was at the forefront of pioneering new ways to generate actionable insights from alternative data. Before that, I successfully built a sell-side equity research franchise based on proprietary data and non-consensus insights. After moving on from UBS Evidence Lab, I’ve remained active in the intersection of data, technology, and financial insights. Through my extensive experience as a purchaser and creator of data, I have gained a unique perspective, which I am sharing through the newsletter.
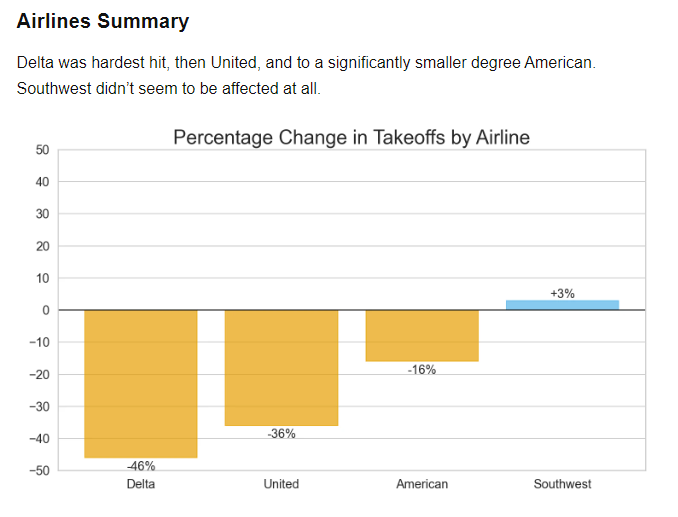
Of the many industries affected by the Blue Screen of Death (BSOD, A stop error screen displayed on a Windows computer system after a fatal system error, also known as a system crash, which causes the system to fail), Delta Airlines was seemingly harder hit than other airlines and, of note, Southwest had less impact than others.
Delta’s CEO claimed $500 million in losses.
Bastian, speaking from Paris, where he traveled last week, told CNBC's "Squawk Box" on Wednesday that the carrier would seek damages from the disruptions, adding, "We have no choice." "If you're going to be having access, priority access to the Delta ecosystem in terms of technology, you've got to test the stuff. You can't come into a mission critical 24/7 operation and tell us we have a bug," Bastian said. https://www.cnbc.com/amp/2024/07/31/delta-ceo-crowdstrike-microsoft-outage-cost-the-airline-500-million.html
The initial response
Early responses to the disaster were important, as the absence of accurate statements leads to some filling in the gaps with whatever “truth” they can imagine. CrowdStrike's early admission of fault, along with Microsoft's acknowledgment, alleviated fears of a cyberattack.
Teams across the globe and across many industries worked to solve the specific applications that were down due to the outage, including getting individuals access to the systems restored. They did so even with some of their staff potentially affected by the BSOD, an influx of tickets raised and automated exception reports triggered.
Is there a blame game inside CrowdStrike?
Of course, some people also wanted to use the moment for comedy by pretending to take the blame. And, of course, people across the internet can’t tell satire from reality. Which, as an aside comment, makes me wonder how an AI model would be able to tell satire from reality as it consumes text across the internet via its training process.
This made me think about the real team and managers overseeing this situation, and I wondered if they would face blame and serious consequences. One could only imagine the sinking feeling in the team’s stomach as the reality of the deployment became apparent.
It’s a common acknowledgement across the tech industry that there’s “a rite of passage” by accidentally taking down the application supported by the deployment (similarly, there’s “a rite of passage” for a developer to accidentally run up a massive compute bill on the cloud due to bad code). In companies with a good culture where technologies feel psychologically safe, these are seen as learning opportunities. In the earliest days of Evidence Lab, someone accidentally deleted the database with all the data and analytics. It was a major setback for Evidence Lab, but the person responsible wasn’t let go. They continued their career with UBS and took on more responsibility along the way. While a major setback for Evidence Lab, it was insignificant in the broader context of UBS or the financial markets.
However, the CrowdStrike/Microsoft outage is exceptional. Typically, an application error doesn't result in billions of dollars in economic loss. Can this still be a learning and growth opportunity for CrowdStrike, or will there be blame resulting in terminations?
Using prediction market data on CEO tenure as a data point
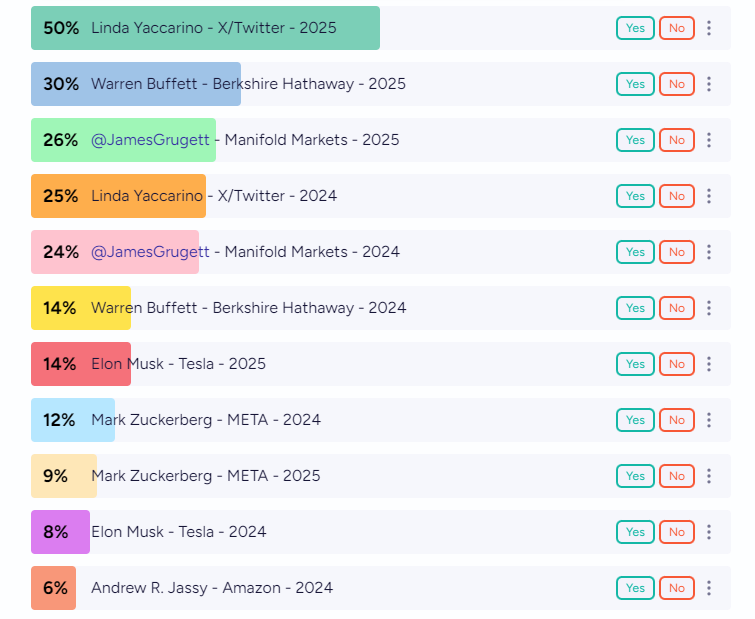
A data point indicating a risk to psychological safety at CrowdStrike is the betting market's 32% probability of a change as of August 4th.
As a comparison to the 32% chance shown above, we need a comparison of other company CEOs to put it in context.
I guess the glass half full point of view is that it’s more likely that the CrowdStrike CEO will remain in his position. But its levels are elevated compared to other CEOs, which suggests there is expected to be accountability in terms of job loss due to the situation. It seems to be trending lower from the original coin flip probability implied by the market.
Can CrowdStrike turn this into a learning moment to sure up their processes and systems to allow for flexibility in adapting their software to new cyber threats without taking down applications dependent on their software?
Learning from errors
There are learnings within CrowdStrike which are being made public, but there are also learnings downstream from the application, as organizations affected by the outage also had to respond rapidly.
On Friday, July 19, 2024 at 04:09 UTC, as part of regular operations, CrowdStrike released a content configuration update for the Windows sensor to gather telemetry on possible novel threat techniques. These updates are a regular part of the dynamic protection mechanisms of the Falcon platform. The problematic Rapid Response Content configuration update resulted in a Windows system crash. Systems in scope include Windows hosts running sensor version 7.11 and above that were online between Friday, July 19, 2024 04:09 UTC and Friday, July 19, 2024 05:27 UTC and received the update. Mac and Linux hosts were not impacted. The defect in the content update was reverted on Friday, July 19, 2024 at 05:27 UTC. Systems coming online after this time, or that did not connect during the window, were not impacted.
The document discussed in detail the timeline of events and explained in more detail the difference between the Sensor Software Code and the Rapid Response Content Configuration. CrowdStrike offered their learnings in their document:
How Do We Prevent This From Happening Again?
Software Resiliency and Testing
Improve Rapid Response Content testing by using testing types such as:
Add additional validation checks to the Content Validator for Rapid Response Content. A new check is in process to guard against this type of problematic content from being deployed in the future.
Enhance existing error handling in the Content Interpreter.
Rapid Response Content Deployment
Implement a staggered deployment strategy for Rapid Response Content in which updates are gradually deployed to larger portions of the sensor base, starting with a canary deployment6.
Improve monitoring for both sensor and system performance, collecting feedback during Rapid Response Content deployment to guide a phased rollout.
Provide customers with greater control over the delivery of Rapid Response Content updates by allowing granular selection of when and where these updates are deployed.
Provide content update details via release notes, which customers can subscribe to.
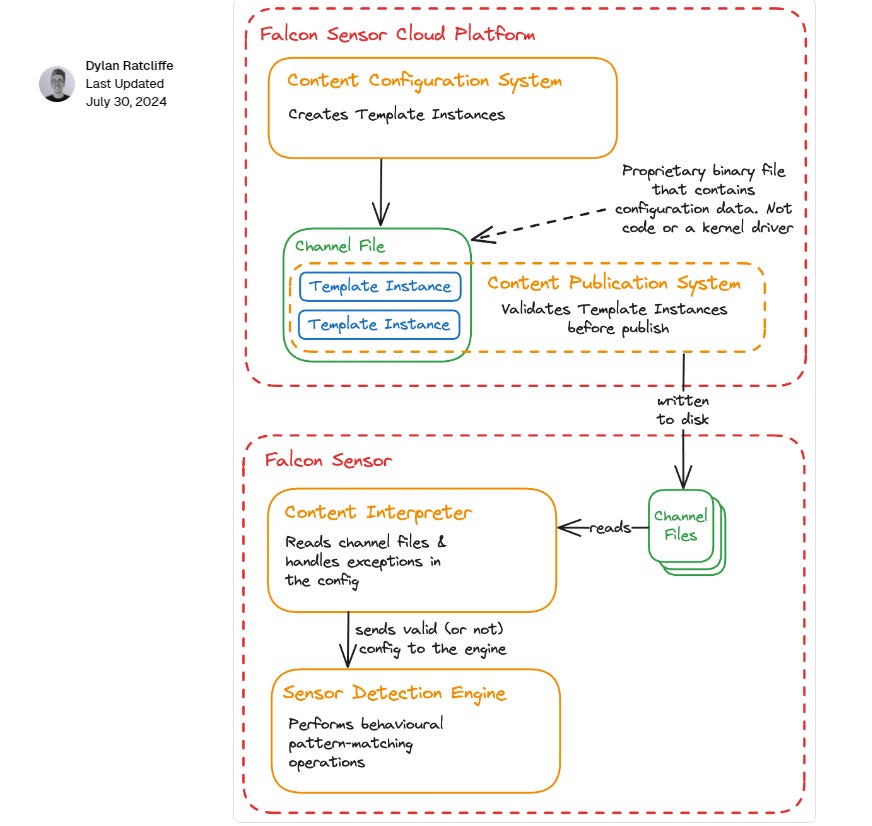
While there is a lot of proprietary terminology here, the configuration mechanism they are describing is not terribly complex or surprising. The sensor appears to be a modular service whose behaviour can be changed by one or many config files (channel files) that contain one or many sets of instructions (template instances). This is similar to the patterns used by web servers like Nginx or Apache where many config files, which in turn contain many “directives” are combined together to configure how the service should behave. The key difference between this situation and that of Nginx or Apache is that you don’t control the config, CrowdStrike do.
You might have noticed that while the above section tells us a lot about how the config works, it doesn’t tell as much about how the config is deployed, as in, which pieces of config should be deployed to which customers, when? We do get a couple of hints in the review, such as: “Template Instances are created and configured through the use of the Content Configuration System, which includes the Content Validator that performs validation checks on the content before it is published.”. But detailed information about testing, internal dogfood-ing, and deployment to early adopters is absent. (Reading between the lines: This would have been a good opportunity to call out testing processes if they existed. I’ll leave it to the readers to decide if this was an oversight or not… )
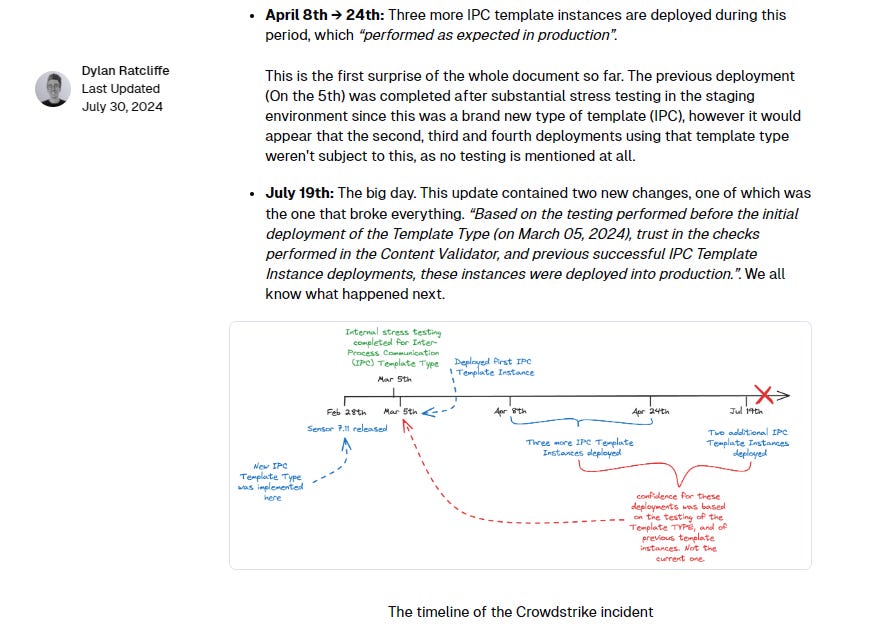
Dylan then goes back through the timeline provided by CrowdStrike to understand the issue more practically. It seems the bug in the content validator was not detected and was trusted to be accurate.
Testing performed on March 5th: This testing covered the new IPC Template Type, but not the specific configuration that was being deployed on July the 19th. There seems to have been a belief within CrowdStrike that as long as the code had been tested, each individual piece of configuration didn’t need to be tested.
Previous successful deployments: The notion that deploying three different pieces of config over a three month period would mean that the fourth different piece of config (for what was still a pretty new feature) wouldn’t cause issues, doesn’t make sense to me. This seems to be an example of a faulty generalisation fallacy7, however potentially there is more information that we are missing. For example maybe they did 1,000 deployments in this period, and the fact that this was only the fifth deployment of this new type was missed. It would still be a faulty generalisation fallacy, but it would be easier to understand.
Trust in the Content Validator: The role of the Content Validator was to “gracefully handle exceptions from potentially problematic content”. This is critically important when operating a kernel-level8 driver as unhandled exceptions will crash the entire machine (as we learned the hard way). In the end, it was a bug in the Content Validator that caused the outage. But this confidence was misplaced, even if there hadn’t been a bug.
Global “chaos monkey” and resolving downstream impact.
Not only does CrowdStrike have an opportunity to learn, so does every organization affected by this event. Effectively, the world had a Chaos Monkey event.
"At Netflix, our culture of freedom and responsibility led us not to force engineers to design their code in a specific way. Instead, we discovered that we could align our teams around the notion of infrastructure resilience by isolating the problems created by server neutralization and pushing them to the extreme. We have created Chaos Monkey, a program that randomly chooses a server and disables it during its usual hours of activity. Some will find that crazy, but we could not depend on the random occurrence of an event to test our behavior in the face of the very consequences of this event. Knowing that this would happen frequently has created a strong alignment among engineers to build redundancy9 and process automation to survive such incidents, without impacting the millions of Netflix users. Chaos Monkey is one of our most effective tools to improve the quality of our services."
Fire drills across many IT teams
All organizations that had employees see the BSOD or their own applications fail went through the fire drill of figuring out solutions quickly. After CrowdStrike updated the software which had the issue, it was up to each IT team to solve the problem of their own infrastructure.
To gauge the recovery, CrowdStrike provided updates.
19-July: Outage began
21-July: “Significant number back online”
Commentary via Post on X: CrowdStrike continues to focus on restoring all systems as soon as possible. Of the approximately 8.5 million Windows devices that were impacted, a significant number are back online and operational.
24-July: 97%
CrowdStrike Commentary: Using a week-over-week comparison, greater than 97% of Windows sensors are online as of July 24 at 5pm PT, compared to before the content update.
29-July: 99%
CrowdStrike Commentary: Using a week-over-week comparison, ~99% of Windows sensors are online as of July 29 at 5pm PT, compared to before the content update. We typically see a variance of ~1% week-over-week in sensor connections.
If a data vendor has a more precise measure of the impact and recovery, it would be valuable to see.
At the start of the article, I used Delta’s story to highlight the financial impact of the outage. Not all Airlines were affected equally. I found an interesting analysis by John Wiseman on of the impact of the CrowdStrike outage on various airline companies, in the TLDR newsletter:
Those who keep score at home will have noticed two primary references for The Data Score article on this topic came from the TLDR newsletter. Worth checking it out: Signup for TLDR Newsletter
The ABC article references the high dependency on Windows and that the terminals required a manual fix at each individual computer system. In John Wiseman’s blog post, he points out that this wouldn’t have been different than other airlines.
Why was Southwest unaffected?
In December 2022, Southwest was the hardest hit by severe weather, unlike its competitors, it’s scheduling system couldn’t keep up with the pace of changes during high demand, causing it to cancel 17,000 flights. This time, Southwest wasn’t affected.
Some airlines, including Southwest and Alaska, do not use CrowdStrike, the provider of cybersecurity software whose faulty upgrade to Microsoft Windows triggered the outages. Those carriers saw relatively few cancellations.
A Fortune article attempted to explain why Delta struggled as a connection to the prior Southwest issues of December 2022.
But as other airlines got back on their feet quickly, Southwest’s problems persisted because the airline relied on outdated internal systems to coordinate crew schedules. When the dust settled, the budget carrier had canceled nearly 17,000 flights in a little over a week.
Kathleen Bangs, a spokesperson for FlightAware and former commercial pilot, explained to Fortune that crew-scheduling systems are extremely complicated, and having to force a complete reset can throw operations into chaos.
“You’ve got all your pilots. That’s like one set of chess pieces on a chessboard,” she said. “Then you’ve got all your flight attendants. That’s another set of chess pieces. And then you have the airplanes and the airports. All of a sudden you get these four groups of chess pieces, and they’re all out of whack.”
In the case of Southwest, Bangs said the antiquated crew scheduling system essentially prevented the airline from recovering from the weather disruptions.
“Once it got behind—and it got so behind it could never catch up—it could never bring the past up to current while still trying to do today and tomorrow’s crew scheduling.”
The similarities between Southwest and Delta aren’t straightforward. Southwest’s initial problem was brought on by an extreme weather event that initially grounded flights, while Delta’s issues were the result of a bug in a software update.
But in both cases the debacle seems to have been compounded by heavy traffic. In a recent note, Delta CEO Ed Bastian said the weekend of the CrowdStrike outage coincided with the airline’s busiest weekend of the summer.
“The technology issue occurred on the busiest travel weekend of the summer, with our booked loads exceeding 90%, limiting our reaccommodation capabilities,” he said.
What’s more, if the factors that precipitated the two meltdowns are different, the effects on crew scheduling appear to be similar. According to Bangs, Delta pilots she’s spoken to have said they were in position, ready to fly, but couldn’t get into the scheduling system, or the system wouldn’t recognize them.
What’s surprising, she said, is that an episode like this could happen less than two years after the Southwest debacle, which should have prompted other carriers to take a closer look at their own systems.
“After what happened with Southwest,” she noted, “and after everybody in the industry hearing for so long, especially from Southwest flight crews, who were very vocal about this, about their frustration with the system, what’s shocking is that it could happen again so soon.”
While it’s not exactly an answer why Delta’s system was hardest hit compared to other airlines that also leverage Microsoft and CrowdStrike, there’s a lesson here for everyone: to have Disaster Recovery plans in place.
What did businesses and industries without a prolonged impact have in common?
What will each organization learn from their experience?
How will their playbooks for outages be updated?
What can be learned from CrowdStrike’s retrospective and root cause analysis?
If you have learned from your own challenges related to the outage, please share them in the comment section below.
Why psychological safety needs to exist even when the stakes are high
CrowdStrike provides cybersecurity protection, where the stakes are high to ensure the software functions correctly without causing harm. However, perhaps equally negative would be a scenario where new cyber threats are detected, but the inability of the organization to effectively apply process and procedures to ensure accurate deployments diminishes the psychological safety of the developers. A scenario where the developers are unwilling or unable to act quickly within the frameworks established could slow the response time to new cyber threats.
There are parallels to business and investment worlds, where data and software are used to make decisions. The stakes are high for an incorrect decision, but it’s not possible to eliminate mistakes completely. The organization itself needs the right culture to navigate uncertainty, including the ability to fail quickly without major consequences, learn, and adapt. It also needs to have in place proper procedures and quality checks to provide guideposts for individuals to navigate effectively.
Not a blank check for sloppy work and poor management
This doesn’t absolve individuals from the consequences of knowingly or unknowingly violating the guidelines and cultural standards. There can be issues where individuals need coaching and support to make the right choices within the frameworks established.
Concerns about lack of accountability and potential complacency are valid.
High-stakes environments require a careful balance of psychological safety and high standards, especially when regulatory and legal factors are to be considered.
Need to balance psychological safety and accountability: Strategies for maintaining accountability include regular training, clear guidelines, and a robust review process while still encouraging a safe environment for reporting and learning from mistakes.
However, most errors happen when people have the best intentions and are making decisions based on the information available to them. Often, the gap lies in the processes or tools, which a learning organization can identify and update while ensuring employees feel supported in making decisions.
Final thoughts on a blame culture vs. Learning learning culture
A culture that plays the blame game will lead to less active changes, limited autonomy to make changes, and less innovation, that could also lead to negative consequences, especially in high-stakes cybersecurity, financial markets, or any competitive industry where the environment surrounding decisions is constantly changing. Top-down decision-making and a fear-driven culture will slow innovation, allowing new entrants and innovative competitors to capitalize on this weakness.
A learning organization is best protected from the next outage, even if mistakes are made along the way. Learning from other companies’ publicized mistakes is important too. Creating process controls from the bottom up is a never-ending journey. It’s important for management teams to create the right balance of oversight and support for bottom-up learning and advancement to support high-quality deployments.
Stress Testing: A testing methodology used to evaluate how a system behaves under extreme conditions, such as high traffic or heavy computational load
Fuzzing: An automated software testing technique that involves providing invalid, unexpected, or random data to the inputs of a program to find security vulnerabilities and coding errors.
Fault Injection: A testing technique used to improve the robustness of a system by deliberately introducing errors or faults and observing how the system responds.
Content Interface Testing: A type of testing that ensures the interactions between different software components or systems function correctly and reliably.
Canary Deployment: A software deployment strategy that releases changes to a small subset of users or systems before rolling it out to the entire infrastructure, used to catch potential issues early.
Kernel-level Driver: Software that operates at the core of the operating system, managing communication between the hardware and the operating system. Errors at this level can cause significant system crashes.
Redundancy (in software): The inclusion of extra components that are not strictly necessary to functioning, used to increase reliability and prevent failure.