
The Paradox of Finding Surprising Insights in Alternative Data
It’s the most exciting moment in alternative data—finding something very surprising that’s not priced into consensus! But then the fear kicks in: “What if it’s not accurate?”

Welcome to the Data Score newsletter, your go-to source for insights into the world of data-driven decision-making. Whether you're an insight seeker, a unique data company, a software-as-a-service provider, or an investor, this newsletter is for you. I'm Jason DeRise, a seasoned expert in the field of alternative data insights. As one of the first 10 members of UBS Evidence Lab, I was at the forefront of pioneering new ways to generate actionable insights from data. Before that, I successfully built a sellside equity research franchise based on proprietary data and non-consensus insights. Through my extensive experience as a purchaser and creator of data, I have gained a unique perspective that allows me to collaborate with end-users to generate meaningful insights.
Institutional Investors are paid to find surprises and also be skeptical of surprises
The goal of leveraging alternative data is to uncover the surprising and often misunderstood aspects of the real world. This is accomplished by analyzing detailed and frequent data points that act as indicators for key performance indicators (KPIs) of companies. The billions of data points harvested1, cleansed, enriched, and aggregated into well-crafted, fundamentally driven metrics are built to be aligned with the uncertainties and debates in the market. Data-driven insights turn “known-unknowns” into “known-knowns”. It’s why the largest asset managers spend tens of millions of dollars (or more) on alternative data.
When an investor’s alternative data tells them there’s a big surprise coming for the market, they dig in deeper to make sure they are not missing something obvious or that an error exists.
But good institutional investors2 are paid to be skeptical. They don’t trust management, they don’t trust pundits, and they don’t even trust their own models.
Good institutional investors know that "All models are wrong, but some are useful”, to paraphrase the quote attributed to George Box.
They start from the assumption that something too good to be true is probably not true. They know that the second they think they fully understand the financial markets, that’s when they will be most surprised by what happens next in the market. They are paid to make predictions, but they know they will often be wrong. The best at predicting share price movements are slightly more accurate than a coin flip. They know they can’t be overconfident with any discovery because they are competing with every investor in the market. It’s very hard to beat the wisdom of the crowd when the crowd is independently arriving at conclusions about their investments while avoiding groupthink/crowded3 trades.
When an investor’s alternative data tells them there’s a big surprise coming for the market, they dig in deeper to make sure they are not missing something obvious or that an error exists.
Big surprises
To be clear, there’s a range of reasonable results from data and real life, and I’m not suggesting that every beat or miss needs this level of rigor outlined below. When I say big surprise, I mean a materially different outcome from consensus4. It’s the kind of beat that could move market prices significantly if it's the right insight to the right question… and not a data anomaly5. We’re talking about a very surprising change in trend that only recently inflected upward. Moderate differences vs. consensus are also important, but they are not going to receive the same level of scrutiny that a truly surprising insight would.
Signal or Anomaly?
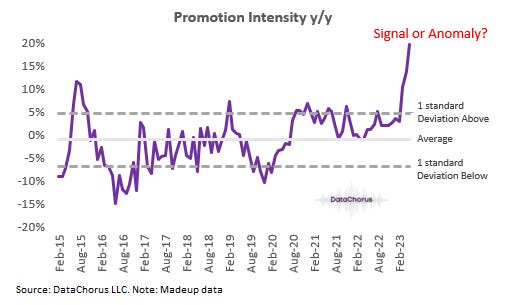
In the early stages of an investor’s use of alternative data, it may take longer for them to take this approach of verifying a true surprise in the data. As trained skeptics of all information and first-time users of Alternative Data, they are really going to want to dig in and be sure before depending on the data's insight. Effectively, the investor’s integrity is put on the line with each big non-consensus investment they make. To be comfortable with a decision that could cause financial and reputational risk, the data must be scrutinized first.
As more experience is gained, it becomes easier to get through the process. And it’s actually reasonable to build steps into the process on an ongoing basis, including automation of reporting and alerting, to help manage the process of verifying big surprises as painlessly as possible. Validating surprising insights should be a scalable undertaking, requiring both data companies and centralized data teams within asset managers to effectively implement the process.
In this newsletter entry
I’ll run through my recommended approach to make sure that the big surprise is answering the right question, providing an insight different than what’s priced in, and how I double check the data integrity to have the highest possible confidence in very surprising data-driven insights.
Make sure we are answering the right question
Understand the consensus answer and what’s priced in
Interrogate the data