
Blending AI and Human Creativity: Generative AI and Content Strategy
A Benchmark Approach: How I use generative AI in creative process. (A bonus Data Score Newsletter Entry for the long-weekend).

Welcome to the Data Score newsletter, your go-to source for insights into the world of data-driven decision-making. Whether you're an insight seeker, a unique data company, a software-as-a-service provider, or an investor, this newsletter is for you. I'm Jason DeRise, a seasoned expert in the field of alternative data insights. As one of the first 10 members of UBS Evidence Lab, I was at the forefront of pioneering new ways to generate actionable insights from data. Before that, I successfully built a sellside equity research franchise based on proprietary data and non-consensus insights. Through my extensive experience as a purchaser and creator of data, I have gained a unique perspective that allows me to collaborate with end-users to generate meaningful insights.
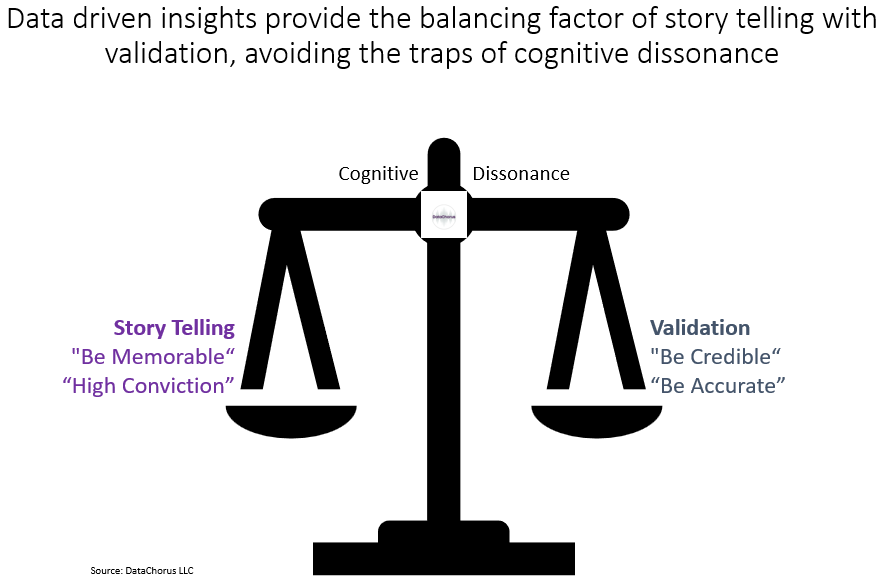
A critical part of the Alternative Data ecosystem is the ability to tell the story of the data. There are two parts to every data story: There’s the validation and accuracy that data provides in answering a critical investment question. But there’s also the memorability of the story that the data tells. A great content strategy meets the needs of the audience by understanding the jobs to be done by data purchasers, which include:
Data Discovery
Data Assessment
Data Integrity
Data Access
A content strategy that is both memorable and provides validation for each of these targeted outcomes will improve the ability of professionals to generate an impact. This is true for data companies creating marketing content, sellside analysts communicating with the buyside1, data sourcing specialists creating content for analysts, data scientists explaining their model to financial professionals, and analysts creating reports for portfolio managers.
The role of AI in my writing process
Content generation is a largely human activity, but increasingly, automation has made it easier to generate content at scale. Large Language Models (LLM)2 have raised the question of whether this could be fully automated. However, hallucinations3 and superficial summaries leave much to be desired.
In this bonus entry of the Data Score Newsletter, I explore how I use generative AI as a resource in the creation process, which I hope will spark ideas for anyone creating formal or informal content in their data insight journey. There’s valuable use cases and especially important limitations associated with generative AI. Long-term, I believe generative AI can be fine-tuned4 to generate validated, memorable content at scale.
First, a thank you for all the support of the Data Score and DataChorus LLC
The first Data Score was published in early April, and I would have expected a slower ramp up in the number of people following the Newsletter compared to what the newsletter achieved so far. I was quite flattered to hear so many people who attended Battlefin were aware of my newsletter - and I was also flattered that “The Data Score” was once mistakenly confused with the very amazing and widely followed “It’s Pronounced Data” newsletter by Dan Entrup:
I very much enjoy writing this newsletter as its own creative act. I’m writing about topics I believe are important and want to put my views out into the community as a benchmark for others to consider in their own approaches. The goal is to make it the start of the conversation. I’m inspired to create more because of the positive feedback… and those who know me well know I have a lot of views on all aspects of the data insights world, so there’s no shortage of topics to write about :)
Shameless request #1: If The Data Score is valuable to you, I would really appreciate it if you would share the newsletter with others who you think would benefit from the content.
Shameless request #2: I always follow up on the positive feedback by asking for ideas for potential topics that you think would be helpful to the broader alternative data community, so please share your ideas you’d like to see covered in the Newsletter.
At Battlefin’s NY conference, one of the themes was the potential productivity impact of Generative AI for the alternative data industry. With the topic already in the air, my conversations about the Data Score often seemed to transition to ideas about how I might be able use ChatGPT in the creation of the newsletter.
I openly shared my process in those conversations — it turns out how I use Generative AI as a tool is surprising to most people. Those conversations sparked the idea for this newsletter entry. I hope this, in turn, sparks more ideas for content creation by leveraging what LLMs are good at and avoiding their limitations.
This bonus edition is the 8th entry of the Data Score:
You can find the past entries in the footnotes5:
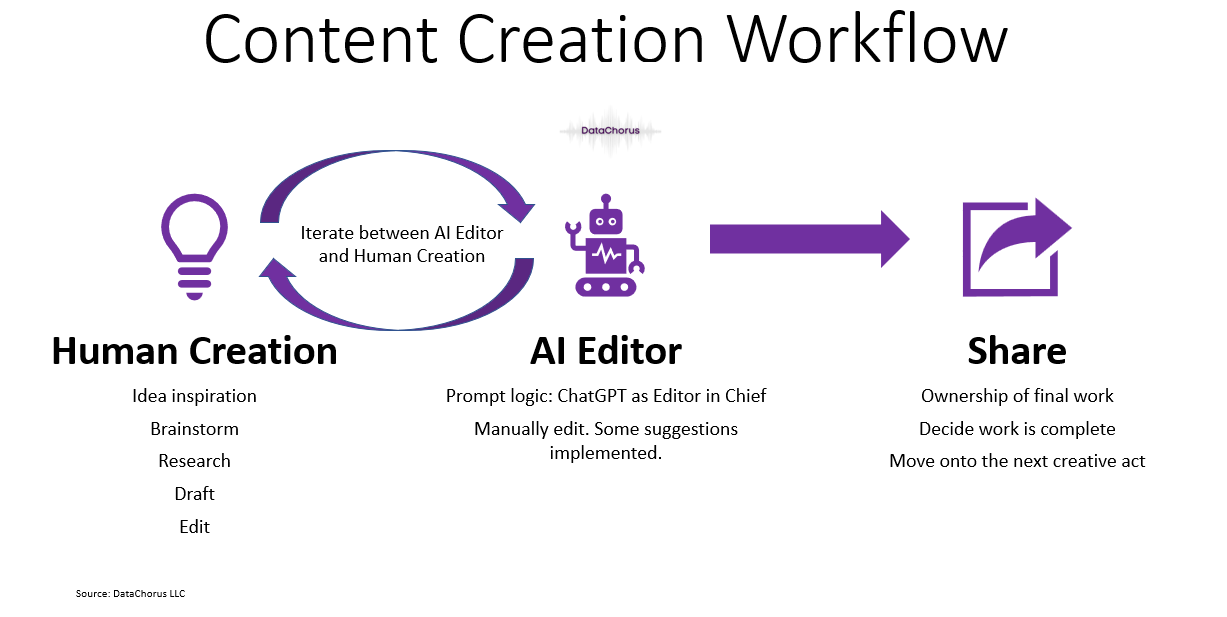
My process starts the old-fashioned way: I write drafts myself without AI
I write the entire first draft of each newsletter myself (multiple edit rounds too). As a former sell-side analyst, I really enjoyed the research report writing process, which focused on the goal of sharing high-impact, actionable insights. At Evidence Lab, I did less writing, so it’s been really enjoyable getting back into writing and sharing ideas regularly.
At any point in time, I probably have four or five partially drafted newsletters on various topics. When inspiration strikes, I take advantage of that to get momentum and finish a draft. Once I’m in the flow, it's usually a matter of a couple hours to complete the draft. But I don’t try to force a topic. I’ll write until I feel good about the topic. If the process feels like pushing a boulder up a hill, I stop and pick up writing on a different topic.
Tech choices in the drafting process
Notion: I like to use Notion for brainstorming and drafting because the platform makes it easy for me to easily get my ideas written down, organize them, and then easily expand the ideas into a full article. It makes it easy to work on the go as well, in between meetings or on the train on my phone. I try to be open to the idea that inspiration can strike at any moment, and capturing the idea in a central place quickly is important to me. Musicians often leave voice notes for themselves when they think of a melody or words for a song because if it’s not recorded, the idea could be lost forever. I feel the same way about ideas for content.
Pocket: Often inspiration comes from other written content, which could be from other newsletters, professional media, marketing content from the alternative data and ML/AI community or academic research. Pocket lets me quickly save the content into a central location, so it’s easy to find for future reference or to dig into when I have more time.
Quillbot: Lately I’ve been using Quillbot AI as a plug-in for spelling and grammar; for a while I was taking the text from Notion over to Microsoft Word to hit F7 and get the spell check review. To be honest, Quillbot is a bit intense because it’s forcing pristine grammar, such as pointing out I’ve used a “-” instead of a “—” or “10am” should be “10a.m.” However, it’s quite good at catching missing Oxford commas, flagging inconsistent spacing between sentences, helping me avoid mixed tenses in paragraphs, and catching moments when I’m being too wordy and losing the clarity of the message… all in real time.
Google: Good old fashion Google searches are a necessary tech choice for fact-checking any references included in The Data Score.
The first round of editing is done manually.
As the drafting process nears its end, I check my own work to make sure I’m following the pyramid principle. Those who have worked closely with me on content know how important the pyramid principle is to my approach because it makes the writing clear, and the takeaways pop off the page (and hopefully those who worked closely with me eventually appreciated that having them rewrite work to meet that structure was worthwhile). The Pyramid Principle: Logic in Writing and Thinking by Barbara Minto
ChatGPT in “Newsletter Editor Mode”
After the draft text is complete and edited by me, I bring ChatGPT into the process as my editor. ChatGPT is great at summarizing text and editing text for clarity and impact. I have been playing with both 3.5 and 4.0 to understand the differences. I’ve also used Google Bard and Bing’s LLM. I tend to go with ChatGPT4.0 for the newsletter because it seems less likely to hallucinate text than the other options.

Summary sanity check: I paste the entire draft newsletter into ChatGPT and ask it to summarize the text. If ChatGPT gives me a summary that’s different than what I’m intending, I know I need to go back and do more work to make the article clearer and more effective. Usually, it provides me with a great summary, which is a nice virtual pat on the back to keep going in the process. Sometimes the summary is written so well and close enough to my style that I leverage the text as a new intro section.
Clarity and impact editorial advice: I ask it to share which parts of the text are not clear and do not have a high impact. It not only returns areas where my wording is unclear, but also makes suggestions to improve the clarity, including rewriting the text and suggesting the kinds of examples that would help support the views shared. It’s typically very valid feedback that I incorporate in the final draft by either rewriting the section myself or leveraging the text from ChatGPT if it’s already written the way I would have done it.
I do get a chuckle out of ChatGPT congratulating me on a well written article before making suggestions for improvement. It seems like the reinforcement learning process taught ChatGPT to praise first before providing constructive criticism. Perhaps a bit of influence from OpenAI’s Sam Altman who said he doesn’t like the feeling of being scolded by a machine. “One small thing that really bothers me about our current thing [ChatGPT 4.0], and we’ll get this better, is I don’t like the feeling of being scolded by a computer. I really don’t. A story that has always stuck with me, I don’t know if it’s true, I hope it is, is that the reason Steve Jobs put that handle on the back of the first iMac, remember that big plastic bright colored thing, was that you should never trust a computer you couldn’t throw out a window.” - Sam Altman on the Lex Friedman podcast: https://lexfridman.com/sam-altman/
Surprise factor: I ask which sections are surprising— ChatGPT’s training texts provide the basis of comparison for answering the prompt. But my real goal in prompting it was to see if the ChatGPT answer on what is surprising matches my expectations. This is one way I know I’m adding value and advancing the understanding of the topic. The surprising items should be emphasized more in the text with the formatting. If ChatGPT points out something that I don’t think should be surprising, it probably means I’m not being clear in my language and I need to edit.
Mutually exclusive and fully exhaustive:
Mutually exclusive: a key part of the pyramid principle is that supporting points are not overlapping. If they are, it’s confusing for the reader, and it means that the ideas need to be regrouped (mutually exclusive). I ask for the list of supporting topics and then ask how they could be grouped into fewer bullet points (typically 3). It will tell me if it is struggling to do it, and that leads to edits on my side.
Exhaustive: Supporting points also need to acknowledge the full range of supporting points, even if they are not the focus of the article. Not addressing an obvious supporting point would leave an unanswered question in the mind of the reader, which could distract from the main points of the article. So, I ask for what I might be missing. ChatGPT is not great at the hierarchy of what’s missing and will generate a lot of topics; usually they are subtopics under what is covered, but sometimes it’s actually a clearly missed line of thinking, which at a bare minimum I need to address by acknowledging it and commenting on why it’s not part of this particular newsletter entry.
“The Jargonator T-800” Hasta La Vista Jargon: I ask ChatGPT to identify jargon that needs to be defined to improve clarity. Not only does it list the jargon, but it also provides definitions. I typically rewrite the definitions to improve accuracy and make them more approachable to the audience, which I include as footnotes.
The hook: I ask it for multiple headline suggestions that summarize the article. I must guide it through the process of brainstorming by giving it prompts about changing the tone or adjusting what the emphasis should be. Some of its suggestions seem like they could be clickbait articles, so I avoid those and re-prompt to guide the suggestions back to more accurate and direct titles. If it gets close enough to something I like, I bring the text in and edit it slightly to be in my tone and style, rather than over-prompt-engineering it to get it to generate the exact text I copy and paste. At some point, it’s just easier for me to write it based on the suggestions.
Image brainstorm: A picture may say 1,000 words, but a good text-to-image prompt is usually around 50 words. My first drafts already have charts and graphs. Even though ChatGPT can’t see or read the charts, I also ask it for image suggestions, memes, potential charts, etc., and it usually comes up with the most obvious suggestions. Those obvious suggestions are a good sanity check. I must confess, I do enjoy its ability to apply popular meme formats to the topic at hand - ChatGPT not only gets the subtle context of the original memes and why they are funny but also fits the content of the newsletter article in the appropriate context. It’s really impressive that a machine can do this. In my process, I reinforce my own view of what makes good charts, graphs, and images, but occasionally there’s a response that makes me think differently about what charts and images to include. Occasionally, I go down the rabbit hole of pasting the suggested text-to-image prompts for Stable Diffusion, DeepFloyd IF or Dall-E to generate an image. Apparently, Mid-Journey is a great one, but I haven’t created a Discord account to access it (should I get on Discord?).
I asked ChatGPT for this article “Please suggest a stable diffusion text-to-image prompt to represent the article” Here’s what ChatGPT created as the text-to-image prompt: “Create an eye-catching image illustrating the seamless collaboration between human creativity and AI-assisted content creation, capturing the key stages of idea generation, brainstorming with ChatGPT, content refinement, impact evaluation, final review, publication, and future considerations. Depict the transformative power of AI in content strategy while emphasizing the importance of human expertise and personal style. Use vibrant colors, engaging visuals, and a balanced composition to evoke curiosity and convey the message of innovation in writing.”
I used that exact prompt in Stable Diffusion and here’s what it came up with. I think I’m going to use it as the cover image for this article:

Why do I not start the process with ChatGPT?
A common suggestion is to prompt ChatGPT with a topic and writing style directions and let it write the first draft. I find that it can put together a very well-structured draft, but the text is not specific enough to have a meaningful impact on the reader. It is written well around the high-level ideas, but often those high-level ideas are already well understood. The writing has to have an impact on the jobs to be done by the reader; it has to advance their thinking, and I don’t think ChatGPT is capable of that yet.
Celebrity chef Dave Chang has a great podcast on the Ringer network. Back in February, they talked about the food writing industry, in which they played a game. They read two articles on food. One is real and one is written by ChatGPT. The link should go right to that part of the conversation on Spotify:
The conclusion of the exercise is that the real writing that was up against the AI writing was not very insightful or valuable; it could be replaced by a machine. It was also noted how bland or artificial the writing of the real articles was, such that it could have been written by AI.
ChatGPT isn’t effective enough at creating high impact yet.
I want to make sure the ideas presented are deep enough into the subject that they advance the reader’s thinking and give ways to try out the ideas in real life or easily benchmark the ideas against their own process. This newsletter focuses on the outcomes needed by readers. So, the tangible and actionable conclusions need to be the center of the article, which requires more subject matter expertise than ChatGPT4.0 has.
My writing style and tone are important to me.
ChatGPT has its own writing style unless you specify it. Its wording choices try to create a text that is warm and somewhat formal. Sometimes it’s a bit flowery with its descriptions, and sometimes it’s overly dramatic about the importance of a topic. And that’s OK. But it’s just not me.
I can try to calibrate6 ChatGPT to get the right tone. I can ask ChatGPT to score my draft writing on a formality scale (from 1-10) and sometimes score the text on various sentiment scales (such as optimistic vs. pessimistic). On the formality assessment, it typically comes back with a score of around 6. When I ask it to rewrite my ideas at a 7 on the formality scale, it writes useful text, but it’s not my style, as it becomes a bit too formal for my tastes. Some of the phrasing generated is comfortable for me to use, but mostly it is just too serious in tone. So, ChatGPT and I usually compromise at a 6.5 formality level when asking it to suggest improved texts.
One thing I’ve learned in this process is that there are times when my writing is more formal and less formal in the same newsletter entry. ChatGPT can’t write with my inconsistent formality. I don’t know if that’s good or bad for me as a writer that my tone shifts slightly depending on the topic, paragraph, or sentence. But it’s my writing style, and I prefer to keep it as me and not a machine.
The final step: share!
“The reason to finish is to start something new” - Rich Rubin
I’m a huge fan of Rick Rubin’s book https://www.amazon.com/Creative-Act-Way-Being/dp/0593652886 and his interviews on the Broken Record podcast
https://www.pushkin.fm/podcasts/broken-record. He has a unique way of getting artists out of their heads and accepting that work should be worked on with high effort while in the process of creating. But when the work is "complete,” it’s time to share it and move on to the next creation. Sharing completed work is what makes the creation process valuable.
How does one know when work is “complete”? Here’s one of many quotes from Rick Rubin on the subject:
“All art is a work in progress. It’s helpful to see the piece we’re working on as an experiment. One in which we can’t predict the outcome. Whatever the result, we will receive useful information that will benefit the next experiment. If you start from the position that there is no right or wrong, no good or bad, and creativity is just free play with no rules, it’s easier to submerge yourself joyfully in the process of making things. We’re not playing to win, we’re playing to play. And ultimately, playing is fun. Perfectionism gets in the way of fun. A more skillful goal might be to find comfort in the process. To make and put out successive works with ease.”― Rick Rubin from The Creative Act: A Way of Being ****
For me “complete” is when I can positively answer
“Have I created an article that provides the intended value or outcome to the reader?”
“Am I happy with the outcome of the process and that I’ve put in the effort to make it worth reading?”
“Is this article something that I’m proud of.”
This applies to what I create today, leveraging ChatGPT as a tool, and would apply in the future to any automated process that helps me create my work.
My current tech-enabled process leads me to make direct edits in my newsletter. Sometimes the process is pushing me to do better because ChatGPT is giving me the exact constructive feedback I need to make the text more impactful. It’s clear the work is not yet done.
I’m appreciative that “A Different Approach to Revenue Estimates Leveraging Alternative Data” https://thedatascore.substack.com/p/a-different-approach-to-revenue-estimates was very well received based on the reads, forwards and open feedback. However, I have to admit the early drafts were simply not good enough to publish, and ChatGPT gave me the feedback I needed to re-write the text multiple times until I got the text into a place where the conclusions were clear, well supported and the overall text had a high impact for the reader. I went through multiple iterations of the process I outlined here until it was ready to be shared. I was finally proud of the work completed and ready to share something that I thought would have a high impact on the readers and lead to more conversations on the topic.
Future State: Human and AI Collaboration as a Symbiotic Relationship
In the future, I do think LLMs can create valuable and memorable content. A fine-tuned LLM could generate content at scale in the future, but it would still need help with the logic as a layer between the data inputs and the output text.
The technology exists today to fine-tune a LLM to solve specific content creation tasks. In the case of The Data Score, the blocker is the small sample size of training materials, with just this entry as the 8th installment. However, I suspect if I write 50+ Data Score entries, I could fine-tune an LLM to write in my style and provide it with an outline of key points to generate, including the examples that make the ideas actionable. I suspect it would be able to write something with high impact. Maybe I will run a test LLM Data Score chatbot after 20 entities and see how it does and report back to you all. Or perhaps I could kindly ask UBS to provide me access to the thousands of research reports I wrote as a sellside analyst on their platform to train the model right now :)
Getting my tone and style right would be a big time saver, but I would still need to provide the logic and insights for the LLM to create a fully formed newsletter entry. This model would very much be a human in-the-loop7 providing the directions.
I think that automation could go further by having other machine learning applications trained on generating logical outputs from raw data. Back in 2019-2021, I was part of a team that experimented with Natural Language Generation (NLG)8 applications on top of alternative data to automatically generate paragraphs and charts highlighting the key takeaways from the latest release of data. It was very much a human in-the-loop approach, curating the output based on our assessment of actual impact. In our case, the outputs were accurate, but getting the calibration of impact relevant to what would actually be material to stock prices required a human in-the-loop. I believe that the human assessment process had repeatable steps and logic, which could also be automated by feeding the model with more reference data and logic rules.
Automated content would certainly still need a human sanity check to ensure the output is not hallucinated or that the conclusions are as intended. My view is that the person or company publishing the content generated by AI has accountability for the AI's output. It would be no different than having a junior staff member create content on behalf of a senior person. The senior person always has accountability for the published content, even if they didn’t write it. In this case, it would be a machine with responsibility for the content creation, but the accountability still lies with the person and company choosing to share it.
Concluding thoughts
Clear and high impact content is a critical part of alternative data because the user of the data insights not only needs the validation ability of the data, but also the memorability of the data story.
I hope this approach is useful for you as a benchmark when creating content on what can be done with technology to have a high impact but keeping the human element in the process.
I also think it’s important to be transparent in the use of AI, which is why I always sign off the article with my name and image. I guess generative AI could do that, but I’m doing this to represent is me who created the article and it’s me taking ownership of the content.
There’s so much to discuss associated with generative AI, and this is just the start of our conversation.
What other ways have you used LLMs to create or edit content? Is some of this process similar to your approach?
Which generative AI tools have been most valuable to you?
Are you concerned about the risks and ethics associated with AI in the creative process?
Would you be interested in a deep dive into training LLMs?
- Jason DeRise, CFA

Buyside vs Sellside: Buyside typically refers to institutional investors (hedge funds, mutual funds, etc) who invest large amounts of capital, and Sellside typically refers to investment banking and research firms that provide execution and advisory services to institutional investors.
Large Language Models (LLMs): These are advanced machine learning models trained on a vast amount of text data. They can generate coherent and contextually relevant sentences by predicting the probability of a word given the preceding words.
Hallucination: In AI, hallucination refers to instances where the model generates information that wasn't in the training data, making unsupported assumptions, or providing outputs that don't align with reality.
Fine-tuning: This is a process in machine learning where a pre-trained model (like an LLM) is further trained on a more specific dataset to adapt to the particular task at hand. For example, fine-tuning ChatGPT could involve training it on a specific author's writing style.
Past entries of the data score:
A Different Approach to Revenue Estimates Leveraging Alternative Data
Explore a fresh approach to revenue forecasting using alternative data, by focusing on the customer journey rather than short-term trends https://thedatascore.substack.com/p/a-different-approach-to-revenue-estimates May 24, 2023
Top questions ahead of Battlefin NYC 2023
Prepare for the upcoming Battlefin conference: spotlighting key questions for panel discussions on generating value from data and technology https://thedatascore.substack.com/p/top-questions-ahead-of-battlefin May 16, 2023
When to Scale or Keep Iterating
Unlocking Product/Market Fit: The Art of Balancing Scale and Iteration in the Alternative Data Sector https://thedatascore.substack.com/p/when-to-scale-or-keep-iterating May 10, 2023
8 point approach to evaluating data partners
The first pitch and demo look great. But then we look under the hood https://thedatascore.substack.com/p/8-point-approach-to-evaluating-data May 3, 2023
Using Alternative Data for long-term investment debates: Tesla thought exercise
Myth: Alternative Data is only valuable for predicting the upcoming quarter. Fact: Alternative Data can be used to improve long-term forecasts https://thedatascore.substack.com/p/using-alternative-data-for-long-term April 26, 2023
Why some data companies struggle to sell to the financial markets
The data deluge: Navigating the challenges of selling valuable datasets to the financial industry https://thedatascore.substack.com/p/why-some-data-companies-struggle April 18, 2023
The Bull Case for Alternative Data
There's palpable pessimism about Alternative Data's impact in financial markets, currently. While justified currently, the newsletter offers a path https://thedatascore.substack.com/p/the-bull-case-for-alternative-data April 11, 2023
Calibration: In the context of AI, calibration refers to adjusting the model's predictions to align more closely with reality or with the user's needs. For instance, adjusting the model to generate more or less formal text based on feedback.
Human-in-the-loop: This is an approach to AI and machine learning where a human collaborates with the AI model during its operation, guiding its learning and correcting its output.
Natural Language Generation (NLG): This is a subfield of artificial intelligence (AI) focused on generating natural language text by the machine. This can be used to produce reports, write essays, or answer questions in a natural, human-like way.